Product Strategy
The PRD Was Never Meant for Machines (Until Now)



For most of the last two decades, Product Requirements Documents, or PRDs, were written with people firmly in mind. Engineers, designers, QA teams, and stakeholders used them as a shared reference point, while the real work of clarifying details happened elsewhere. It happened in meetings, in Jira tickets, in Slack threads, and in the thousands of small decisions teams make as a product slowly comes to life.
That approach still works remarkably well when your builders are human. People are good at interpreting intent. When a requirement is a little vague, someone raises a hand and asks a question. When a workflow is underspecified, the team fills in the blanks using experience and judgment. When two lines in a document quietly contradict each other, someone eventually notices and resolves the tension.
The dynamic changes, however, when the primary builder is no longer a person.
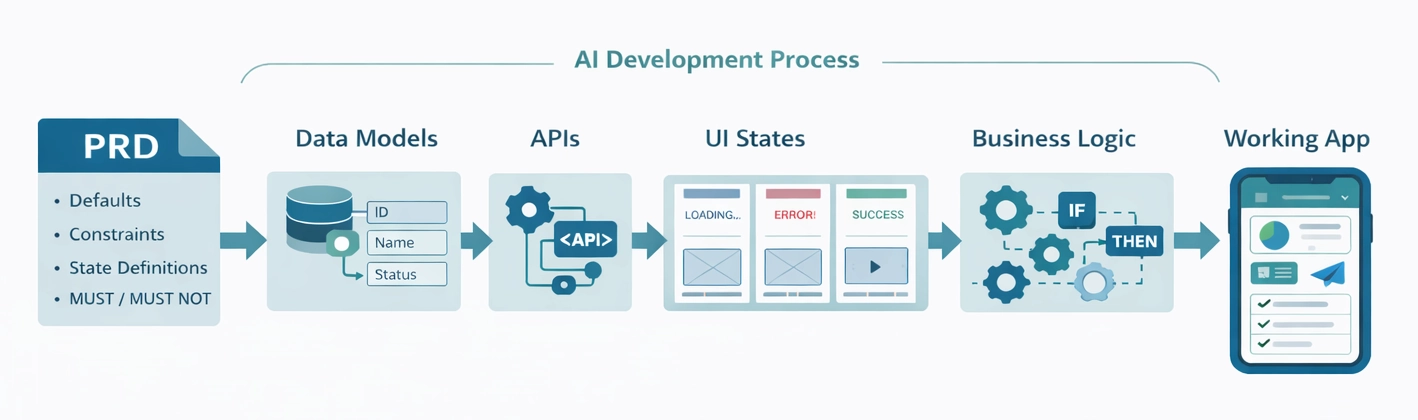
The moment you start building with AI-native development platforms like Lovable, Replit, Base44, Figma Make, and similar tools, the PRD takes on a very different role. It stops being mostly about alignment and starts becoming about execution. It is no longer just a description of what you want to build. It becomes the artifact the system uses to generate schemas, APIs, UI scaffolding, business logic, state machines, and all the connective tissue that makes an application actually work.
If you have ever fed a traditional PRD into an AI builder and received an MVP that looked reasonable at first glance but behaved strangely in edge cases, or quietly expanded beyond its intended scope, you have already felt this shift. The tool did exactly what it was told, just not what you expected.
At Raindrop Digital, this realization sits at the center of how we build modern software. Over time, we have learned that the biggest predictor of a smooth AI-enabled build is not the specific platform you choose, but the quality and structure of the requirements you give it. What follows is a practical guide to how PRDs change when they are written for machines first, while still remaining readable and useful for humans.
Before diving deeper, it helps to name the thing we are talking about. The language is still evolving, but the clearest terms we use are AI-native development platforms and LLM-driven application builders. These systems take natural language requirements and infer application structure from them, often generating UI, data models, APIs, and workflows in a single pass.
That distinction matters because it changes what the platform is actually listening for. A human reader can usually understand what you meant, even if the wording is imperfect. An AI builder has to decide what you meant in a way that can be converted into concrete artifacts, and it tends to do that by mapping language into structure.
Once you start thinking about these platforms less as teammates and more as structure extractors, the changes required in PRD writing stop feeling excessive and start feeling inevitable.
At the heart of this shift is a simple difference in how ambiguity is handled. Humans resolve ambiguity through conversation. AI systems resolve ambiguity through assumptions.
When a human engineer reads a requirement like “users should be able to manage their account,” they instinctively start asking follow-up questions. Does that include changing an email address, resetting a password, deleting the account, or updating billing information? An AI builder does not ask those questions. It selects an interpretation, generates features around that interpretation, and moves on.
Because of this, the role of the PRD changes. Instead of asking whether the document will help a team align, it becomes more useful to ask whether the document can be translated into deterministic system behavior without anyone needing to interpret intent along the way.
This does not mean vision or storytelling disappear from the PRD. It means that the parts of the document that drive implementation now require a level of clarity that was not always necessary before.
Traditional PRDs often read like essays. They include a problem statement, a set of user stories, a few rough workflows, and a definition of success. That style works because humans are good at connecting the dots between narrative and system behavior.
AI-native PRDs still benefit from context, but they cannot stop there. They have to define the system in a way that can be executed without interpretation.
In practice, this means the PRD starts to behave like a blueprint. It specifies what exists, how it behaves, and what happens when things go wrong. It separates Phase 1 from everything else with intention. It declares defaults so the system does not invent them. It defines data models alongside workflows instead of treating them as something that will be figured out later.
When written this way, the PRD becomes a high-leverage artifact. It can be reused across tools, shared with human teams, and carried forward into future phases without losing fidelity.
Once the PRD becomes an execution input, certain types of information suddenly carry much more weight than they used to.
One of the most important shifts is how scope boundaries are treated. Many teams underestimate how aggressively AI builders fill in gaps, which is why “what not to build” becomes just as important as what to build. A human-oriented PRD might say that Phase 1 focuses on basic user management and assume everyone understands where that stops. An AI-oriented PRD needs to spell that boundary out. If Phase 1 includes registration, login, logout, and password reset, that should be explicit. If it does not include roles, permissions, team accounts, or single sign-on, that should be explicit too.
Defaults are another area where expectations need to change. In human teams, missing information becomes a conversation. In AI builds, missing information becomes an invented default, and those defaults show up later as surprising product behavior. Sorting order, pagination, validation rules, empty states, permissions, error handling, and network failures all benefit from declared defaults. Even a single sentence that clarifies a default can save hours of cleanup.
There is also a shift away from thinking purely in screens and toward thinking in states. AI builders can generate UI quickly, but UI without defined states tends to feel fragile. Defining what a user sees when data is loading, when no data exists, when a request fails, or when an action succeeds gives the system enough information to generate transitions that feel intentional and trustworthy.
Finally, data models move to the center of the PRD. In many organizations, data modeling lives in a separate document or is discovered during engineering. AI-native builds work best when entities, fields, constraints, and defaults are treated as first-class requirements. When the model is explicit, generated APIs and UI tend to align. When it is vague, teams often encounter mismatched fields and confusing state that takes time to untangle.
As the role of the PRD changes, so does the way it needs to be written. One of the most common misconceptions is that AI-native PRDs should be shorter because the tool will figure out the details. In practice, the opposite is often true. Precision matters more than brevity.
Words that feel obvious to humans need to be translated into operational meaning. When a PRD says a system should be “secure,” a human infers authentication, hashed passwords, least-privilege access, and sensible logging. An AI builder needs those expectations spelled out. When a PRD says a system should scale, a human imagines caching or asynchronous processing. An AI builder may introduce complexity you did not intend.
Consider a common feature request for project-based products: users can invite teammates to collaborate.
That sentence works well in a human PRD because it sets direction and leaves room for design and engineering to fill in details. For an AI builder, however, it hides all the important questions. Who can invite someone? What information is collected? How is it validated? Does the invitation expire? What happens if the email already exists or is invalid?
An AI-native PRD does not need to become rigid, but it does need to surface those decisions. It should describe the actor, the trigger, the steps, and the system response. It should define validation rules, error states, and acceptance criteria. When written this way, the AI has enough information to generate something that behaves correctly, not just something that looks correct from a UI perspective.
When people talk about AI-enabled product development, they often focus on speed. In our experience, the more important advantage comes from reduced ambiguity.
Clear requirements reduce regeneration loops because the system produces the right structure earlier. Explicit boundaries prevent scope creep because the system does not invent features. Declared defaults keep behavior consistent across the product. Teams that lose time cleaning up AI-generated code almost always trace the problem back to a PRD that left too much open.
Over time, this creates a compounding effect. A well-written PRD becomes a reusable asset that can be fed into multiple builders, shared with human teams, and used as the reference for future phases.
Most teams struggle when they treat the AI builder like a junior engineer who will ask clarifying questions. In reality, the system silently decides.
Other issues tend to follow the same pattern. Aspirational language replaces measurable behavior. Defaults are left implicit. Phase 1 boundaries are underspecified. The result is often an MVP that looks polished, but behaves unpredictably and is harder to test than it needs to be.
These problems are not mysterious. They are the natural result of using documents written for humans as input for machines.
None of this makes product managers less important. If anything, it raises the bar.
The work moves earlier in the process and becomes more leveraged. Translating product intent into precise, executable requirements becomes one of the most valuable skills on a modern team. Teams that do this well ship faster, test earlier, and iterate with more confidence.
When we build with AI-native development platforms, we treat the PRD as the first version of the product itself. It is the blueprint that determines how the system is generated, how the data model is shaped, and how predictable the final application will be.
We start with a structured PRD approach that forces clarity in the places AI builders tend to improvise. Phase 1 scope boundaries are explicit so the MVP stays focused. Negative space is intentional. Screens and navigation are defined, but equal attention is paid to states and transitions, because that is where most AI-generated products break down. Entities and fields live directly in the PRD so the system has a single source of truth. Defaults are declared alongside features so behavior stays consistent. Requirements are written to be testable, because testability is the fastest path to quality when you are iterating quickly.
For clients, this translates into fewer surprises and faster progress. If you bring us an idea, a rough concept doc, or even a half-written PRD, we help turn it into an AI-ready execution blueprint that produces cleaner builds and fewer regeneration cycles. If you already have a team experimenting with these platforms, we help tighten your specs so iteration becomes faster instead of messier.
If you are a founder trying to ship an MVP, or a product leader looking to modernize how your team builds, we would love to talk. A short working session is often enough to identify where ambiguity will cause downstream problems and what an AI-native PRD should include for your product. From there, we can support you with PRD development, rapid prototyping, or a full AI-enabled build.
If there is one immediate takeaway, it is this: write your next PRD as if the reader cannot ask questions.
That mindset naturally leads you to define boundaries, declare defaults, describe states, and make data models explicit. The PRD stops being a narrative and becomes a blueprint.
When that happens, AI-enabled product development feels less like an experiment and more like a dependable advantage.


